
A lot of time and money is spent trying to optimise code so that it can be as fast and efficient as possible, and within the field of data science this is becoming even more important due to the vast datasets that are now required to be processed.
A simple, and often overlooked, way of achieving code optimisation is just to make sure that your language of choice, and associated libraries, are as up to date as they can reasonably be.
You will probably be surprised how relatively little time and effort, can result in some significant benefits.
Introduction #
It is a fairly obvious statement to say that staying up to date could help “optimise” your code, but blindly updating your software or libraries without understanding what is changing is potentially a recipe for disaster.
By the end of this article you should have a good idea of why you should stay up to date. You will have a solid plan of action to ensure you can hit a balance between ensuring you are optimised, and not wasting valuable time. In addition, you will also be aware of the potential pitfalls that can arise, and how to avoid them.
To round things off, a concrete example using the latest release of NumPy (1.24.0) to illustrate the real world benefits of keeping your software and libraries bang up to date.
Why should I stay up to date? #

The simple answer is that you can benefit from items such as:
- brand new features
- optimisations
- bug fixes
All implemented for you by people who know software well, because remember…
You are not a software development expert #
If you are a data science professional (or enthusiast), which I’m going to assume you are, then your main concern is processing, manipulating and analysing data to gain insights and predictions.
Although you may have a certain level of competence with regard to software development, and general coding, it would be fair to say that it is not your expertise.
As such, it is perfectly reasonable that you rely on a high level intuitive language (Python, R, Matlab etc.), and a mountain of libraries that provide a whole host of functionality and optimisation relevant to your field of work. Allowing you to concentrate on your profession.
Rely on the experts, they know better #
If you can build optimisation into your code, great! But it should not be the thing that is consuming your time.
As it turns out, there is an army of other professionals, who know software development extremely well. They are working hard to ensure the language and libraries you use are optimised, and constantly improved. Providing you with the exact tools you need to apply to your work.
However, to take advantage of these optimisations you need to pay attention, or you may be missing out.
Read the release notes, it’s important #

Photo by Pixabay
New versions of both the language, and associated libraries, are released with surprising regularity. However, if you don’t pay attention to what is actually changing, then you may miss out on the potential benefits, or introduce bugs / nonsensical parameters.
A good example of both of these situations is an algorithm update applied to the NumPy np.in1d function in NumPy 1.24.0, which is also utilised in the widely used np.isin function.
np.in1d(used bynp.isin) can now switch to a faster algorithm (up to >10x faster) when it is passed two integer arrays. This is often automatically used, but you can usekind="sort"orkind="table"to force the old or new method, respectively.
Missing out on gains #
It is important to note in the quote above that kind="table" is “often automatically used”, which implies not always.
You could be missing out on a 10x speed gain
You could be missing out on a 10x speed gain just because you didn’t meet the requirements set by the developers to automatically use the new method:
If None, will automatically choose ‘table’ if the required memory allocation is less than or equal to 6 times the sum of the sizes of ar1 and ar2, otherwise will use ‘sort’. This is done to not use a large amount of memory by default, even though ‘table’ may be faster in most cases.
If you read the release notes, then simply adding kind=”table” in the method parameters would be the simple change you needed to ensure a significant benefit in speed of execution, regardless of memory allocation.
Note: this automatic selection is likely introduced to ensure the new method doesn’t cause bugs in your code. There are cases where it could use more memory than the previous method, which may be a problem in memory restricted environments. Very sensible edge case coverage by the developers.
Introducing bugs or confusing code #
If you don’t set the new parameter (because you didn’t read the release notes), then very sensibly the developers set a default.
If None, will automatically choose ‘table’ if the required memory allocation is less than or equal to 6 times the sum of the sizes of ar1 and ar2.
Great! So you may automatically get a speed up of 10x. However:
If ‘table’ is chosen, assume_unique will have no effect.
In this case “assume_unique” having no effect is a minor problem, as the developers look like they have covered edge cases to ensure that if you previously assigned “assume_unique” it will just be ignored.
However, it is messy, as your code specifies a parameter that is irrelevant, which could cause confusion for other people (or even you) in the future.
It is also worth noting that there may be cases where the developers weren’t so thorough, or breaking changes couldn’t be avoided. If that happens, then you will suddenly have code that doesn’t run.
New methods #
Apart from potentially missing out on the improvement for the methods you already use in your code, you may miss out on completely new methods that would be of potential use to your project or workflow.
In a previous article about one hot encoding data I touched on a new method implemented in the recently released Pandas 1.5.0 called from_dummies(), which is a reversal for get_dummies(), a commonly used one hot encoding method from Pandas:

Page not found | Towards Data Science
Publish AI, ML & data-science insights to a global community of data professionals.
Prior to the release of this method, reversal of the one hot encoding would have been a manual procedure.
There are a whole host of new methods created across the libraries that you use, but the only way to be aware of when they appear is to review the release notes.
whatever method the developers have implemented will be optimised and less prone to bugs
…and remember, it is likely that whatever method the developers have implemented will be optimised and less prone to bugs than something you have coded yourself. They are professional software developers after all, and producing bug free well tested code is no easy feat.
A strategy to keep up to date #

Photo by Patrick Perkins on Unsplash
Time is money, as the famous aphorism goes.
The reality is that a typical project may include a mountain of libraries, so it may not be practical to read the release notes for every library, for every tiny update, so it may be wise to prioritise.
Update on specific release points #
It is quite common to see numbering conventions that include three numbers separated by dots. For example the current release of NumPy is 1.24.0.
Being aware of what these numbers (generally) signify can help plan when to pay attention:
- Major version number (1.24.0): large and significant changes to the software or library. Can include changes that are not backward compatible. This requires careful review before upgrading.
- Minor version number (1.24.0): typically a minor feature change / changes, or a larger set of bug fixes.
- Patch version number (1.24.0): typically a smaller set of bug fixes.
If the major version number changes it is absolutely essential that you review the release notes, as there could be breaking changes (i.e. your code could stop working completely in some cases).
The minor version number change is something you should be paying attention to, as it is optimal in terms potential gains, and new or improved methods.
The patch version number can generally be passed over if you don’t have time, unless you are waiting for a known bug to be fixed.
Pick the most important libraries #
If time is of the essence, you should pick the libraries that are most utilised, or most relevant to the project (i.e. those with the biggest impact), and keep up to speed with any relevant changes as updates arrive. As detailed in the previous section this should involve mainly paying attention to major and minor version number changes.
It is not essential that you update the library for every patch release, but keeping track of the changes that are published will give you the opportunity to update when it is beneficial to the project.
In reality, the smaller the update you apply, the easier it is to pin down bugs when they do occur, reducing time taken for mitigation, and lessening the risk involved.
Update strategy - Summary #
- Pay attention to major version number changes for ALL libraries.
- Pay attention to minor version number changes for libraries that are most utilised, or most relevant to the project
- Patch version number changes can mostly be passed over without review, unless you are actively waiting for a bug to be fixed
The potential dangers of upgrading #

Photo by Raúl Nájera on Unsplash
As already discussed, there are some real gains to be had from keeping up to date, but it can also cause unwanted problems, and lost time, due to debugging new errors.
Again, this can mostly be avoided by paying attention to the release notes.
I will refer you to the release notes of NumPy for version 1.24.0 as an example of what to expect. It is well laid out with lots of information (not always the case with all libraries/software):

Release notes — NumPy v2.4 Manual
© Copyright 2008-2025, NumPy Developers.
The main problems that you will face are generally due to one of the following.
Deprecations / Expired Deprecations #
This is probably the main item to pay attention to. When a method becomes deprecated it will eventually be removed (timescales vary). This is excellent as, assuming you are aware of the deprecation being applied, it gives you time to implement a work around, or switch to an updated method from the library.
However, if you are looking at the release notes and notice one of your methods is listed in expired deprecations, then an immediate fix is required before upgrade, as your code will literally stop working.
Compatibility notes / changes #
This is less severe than a deprecation, but can be tricky as they can change behaviour and/or outputs of functions. Something you may not immediately notice if you weren’t aware of it.
array.fill(scalar) may behave slightly different
numpy.ndarray.fillmay in some cases behave slightly different now due to the fact that the logic is aligned with item assignment.Previously casting may have produced slightly different answers when using values that could not be represented in the target
dtypeor when the target hadobjectdtype.
“May behave slightly differently” is about as vague as it gets! A perfect example of something that could cause ‘interesting’ bugs if it is relevant to your code. The above would be worth looking into should you have a very sensitive implementation that uses this function.
What if I can’t upgrade? #

Photo by Towfiqu barbhuiya from Pexels
In industry the reality is that you may have limitations on the upgrade process that are outside of your control. This could be caused by a choice of base operating system / container, or due to limitations in other areas of the project you are working on that require very specific versioning.
Remember, without solid information, no decisions can be made.
However, it is still worth keeping up to date with the developments of key packages and libraries. If nothing else it is ammunition to push for what might be quite a complicated, and/or costly, upgrade process to be put into action, as the benefits may outweigh the upgrade cost. Remember, without solid information, no real decisions can be made.
A concrete example of the benefits of staying up to date #

Photo by Rodolfo Quirós from Pexels
Fairly recently, NumPy had a minor version number change from 1.23.5 to 1.24.0. As explained in an earlier section of this article, a minor version number change, can result in “minor feature changes”, rather than just the simple bug fixes that a patch update would bring.
A couple of these “minor feature changes” claim to result in significantly sped up versions of their original functions:
np.in1d
np.in1d(used bynp.isin) can now switch to a faster algorithm (up to >10x faster)
NumPy comparison functions
The comparison functions (
numpy.equal,numpy.not_equal,numpy.less,numpy.less_equal,numpy.greaterandnumpy.greater_equal) are now much faster as they are now vectorized with universal intrinsics. For a CPU with SIMD extension AVX512BW, the performance gain is up to 2.57x, 1.65x and 19.15x for integer, float and boolean data types, respectively (with N=50000).
Testing the claims #
Although I have no reason to doubt the numbers, I thought it might be interesting to test it out in practise, so the following sections will run benchmarks between the old an new versions to see what real world speed gains can be realised.
Notebooks #
All the code that follows is available in jupyter notebooks.
This section gives details on the location of the notebooks, and also the requirements for the environment setup for online environments such as Colab and Deepnote.
The raw notebooks can be found here for your local environment:
notebooks/python-libraries-update at main · thetestspecimen/notebooks
Jupyter notebooks. Contribute to thetestspecimen/notebooks development by creating an account on GitHub.
…or get kickstarted in either deepnote or colab.
Python 1.24.0:
![]()
![]()
Python 1.23.5:
![]()
![]()
Environment Setup — Local or Deepnote #
Whether using a local environment, or deepnote, all that is needed is to ensure that the appropriate version of NumPy is available. The easiest way to achieve this is to add it to your “requirements.txt” file.
For deepnote you can create a file called “requirements.txt” in the files section in the right pane and add the line:
numpy==1.24.0(change the version number as appropriate).
Environment Setup — Colab #
As there is no access to something like a “requirements.txt” file in colab you will need to explicitly install the correct version of NumPy. To do this run the following code in a blank cell to install the appropriate version:
!pip install numpy==1.24.0(change the version number as appropriate).
Then refresh the web page before trying to run any code.
The test #
The following speed tests were run to give an overview of the improvements to the np.in1d and np.equal methods when using the latest NumPy version (1.24.0) compared to the previous version (1.23.5):
- Two integer arrays with length 50000 using method
np.equal(method run 1 million times) — should be up to 2.75x faster with numpy 1.24.0 according to the documentation - Two boolean arrays with length 50000 using method
np.equal(method run 1 million times) — should be up to 19.15x faster with numpy 1.24.0 according to the documentation - Two integer arrays compared using
np.in1dusingkind="sort"(method run 10 thousand times) — this method is available in both numpy 1.23.5 and 1.24.0 — should be the same speed in numpy 1.23.5 and 1.24.0 (a good cross-check between notebooks to ensure that the results of the other tests can be directly compared) - Two integer arrays compared using
np.in1dusing the newkind="table"method (method run 10 thousand times) — this method is only available in numpy 1.24.0 — should be up to 10x faster than the “sort” method according to the documentation
Input data #
Timeit setup #
Results — NumPy 1.23.5 #
Results-NumPy 1.24.0 #
Summary #
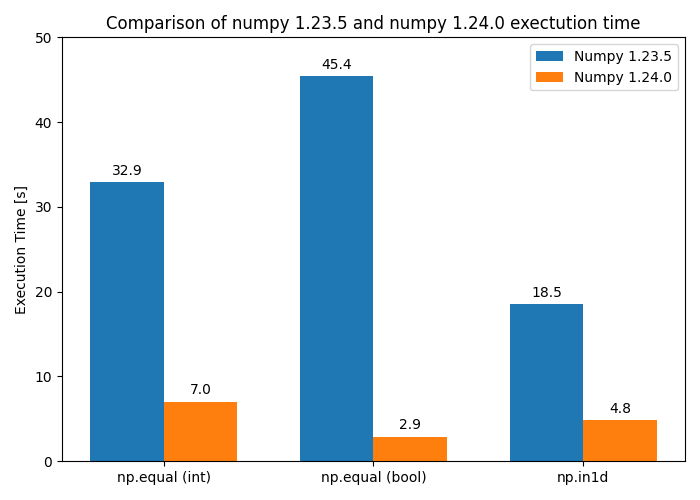
Results comparison — Image by author
As you can see from the results sections, the results achieved are roughly inline with what was expected, and all methods achieve an increase in speed of execution:
- Two integer arrays using method
np.equal— 4.67x faster with numpy 1.24.0 - Two boolean arrays using method
np.equal— 15.56x faster with numpy 1.24.0 - Two integer arrays compared using
np.in1dusing thekind="sort"method — more or less exactly the same execution time using numpy 1.23.5 and 1.24.0 as expected (18.5 seconds for 10000 iterations) - Two integer arrays compared using
np.in1dusing the newkind="table"method — 3.84x faster with numpy 1.24.0 and the newly introducedkind="table"method
Conclusion #
The efforts of software developers to constantly improve the languages and libraries that we all use on a daily basis should not be ignored. It is one of the easiest and most accessible ways to improve the efficiency, speed and reliability of your projects code.
As you can see from the very small example outlined in this article, the benefits can be quite significant. All it takes a little organisation, and the willingness to invest some time into reviewing the release notes for your most important libraries / software.
🙏🙏🙏
Since you've made it this far, sharing this article on your favorite social media network would be highly appreciated. For feedback, please ping me on Twitter.
...or if you want fuel my next article, you could always:

Published