
Having a GPU (or graphics card) in your system is almost essential when it comes to training neural networks, especially deep neural networks. The difference in training speed of a fairly modest GPU is a night and day difference when compared to a CPU.
….but at what point might you consider jumping into the realms of professional, rather than consumer, level GPUs? Is there a huge difference in training and inference speed? Or is it other factors that make the jump compelling?
Introduction #
The aim of this article is to give you an idea of the main differences between a GPU you might use as a normal consumer (or starting out in machine/deep learning), and those used in higher end systems. The type of systems that might be used in the development and/or inference of advanced deep learning models.
Apart from being an interesting exercise in understanding the distinctions between cutting edge pro equipment and consumer level hardware in terms of pure processing speed, it will also highlight some of the other limitations that are present in consumer level GPUs, and associated systems, when dealing with cutting edge deep learning models.
Which GPUs are you referring to when you say “Pro” or “Consumer”? #
The “real world” differences will be covered in the rest of the article, but if you want a solid technical distinction, with example graphics cards and specifications, then this section should cover it.
As detailed in one of my previous articles, NVIDIA are the only sensible option when it comes to GPUs for deep learning and neural networks at the current time. This is mainly due to their more thorough integration into platforms such as TensorFlow and PyTorch.
Making the distinction between professional and consumer, in terms of specifications from the manufacturer, is therefore relatively straight forward.
Anything from the following page is the current batch of NVIDIA’s consumer graphics cards:
NVIDIA GeForce Graphics Cards
GeForce RTX 50 series, 40 series & more.
…and professional level GPUs:
NVIDIA RTX PRO in Desktops
The World’s Most Powerful Platform for AI, Graphics, and Simulation.
There are also GPUs, mainly used in data centres, that go beyond even the pro level graphics cards listed above. The A100 is a good example:
NVIDIA A100 GPUs Power the Modern Data Center
The fastest data center platform for AI and HPC.
You can also get an idea of the system specifications and GPUs being used in professional data centre and workstation systems certified by NVIDIA:
NVIDIA-Certified Systems — NVIDIA Certification Programs Documentation
This document lists the systems that have been tested with the latest NVIDIA GPUs and networking and are evaluated by NVIDIA engineers for performance, functionality, scalability, and security.
The Plan #
I generally find that a real demonstration (or experiment) is the best way to illustrate a point, rather than just relying on specs and statistics provided by the manufacturers.
With that in mind, although the article will discuss the relevant statistics, it will also directly compare three different GPUs (pro and consumer), at differing levels of sophistication, on the same deep learning model.
This should help to highlight what is important, and what isn’t, when considering whether a professional level GPU is for you.
The GPU Specs — A Summary #

For the experiment, there will be three different graphics cards, but four levels of comparison:
- NVIDIA RTX 1070 (Basic)
- NVIDIA Tesla T4 (Mid range)
- NVIDIA RTX 6000 Ada (High end)
- 2 x NVIDIA RTX 6000 Ada (Double high end!)
So how do these different graphics cards compare in terms of raw specs?
| GPU | Memory | CUDA Cores | Tensor Cores | FP32 [TFLOPS] | Generation | Power |
|---|---|---|---|---|---|---|
| RTX 6000 Ada | 48GB | 18176 | 568 | 91.1 | 8.9 (Ada Lovelace) | 300W |
| RTX 4090 | 24GB | 16384 | 512 | 82.6 | 8.9 (Ada Lovelace) | 450W |
| Tesla T4 | 16GB | 2560 | 320 | 8.14 | 7.5 (Turing) | 70W |
| GTX 1070 | 8GB | 1920 | 0 | 6.46 | 6.1 (Pascal) | 150W |
Comparison of different graphics cards
Note: I have included the RTX 4090 in the table above as it is the pinnacle of current consumer level graphics cards, and probably the best direct comparison to the RTX 6000 Ada. I will reference the 4090 throughout the article as a comparison point, although it will not feature in the benchmarks.
If the table above is just a load of number with no meaning, then I recommend my previous article which goes over some of the jargon:

How to Pick the Best Graphics Card for Machine Learning | Towards Data Science
Speed up your training, and iterate faster
The Professional System #

A view from all angles of the professional workstation utilised in this article. Image via Exxact Corporation under license to Michael Clayton
One of the problems with producing an article like this is that you need access to a professional level system, and therefore one of the main hurdles is…cost.
Fortunately, there are companies out there that will give access to their equipment for trial runs, to allow you to see if it fits your needs. In this particular case Exxact have been kind enough to allow remote access to one of their builds for a limited period so I can get the comparisons I need.
…the workstation is worth in the region of USD 25,000
To drive home my point about how much these systems can cost I estimate the workstation I have been given access to is worth in the region of USD 25,000. If you want to depress (or impress?) yourself further you can take a look at the configurator and see what can realistically be achieved.
Incidentally, if you are seriously in the market for this level of hardware you can apply for a remote ‘‘test drive’’ too:
ExxactAccess+ Test Drive | Validate Workloads on 8x GPUs | Exxact Corp
ExxactAccess+ offers remote validation with up to 8x NVIDIA RTX PRO Blackwell GPUs. Validate your unique workload performance before you invest in your new Exxact system.
These are the complete specs of the “professional” system for those that are interested:
| Component Type | Component |
|---|---|
| Motherboard | Asus Pro WS WRX80E-SAGE SE WIFI-SI |
| CPU | AMD Ryzen Threadripper PRO 5995WX 64-core 2.7GHz/4.5GHz Boost 280W |
| GPU | 2x NVIDIA RTX 6000 Ada |
| RAM | 8x 64GB DDR4 3200MHz ECC Reg |
| SSD | 1TB M.2 NVMe PCIe 4.0 / 4TB M.2 NVMe PCIe 4.0 |
| Power | 2000W Modular ATX PS2 80Plus Platinum |
| Cooling | 360mm AIO CPU Liquid Coole / 3x 120mm 1700RPM Fans |
| Case | Fractal Meshify 2 XL |
Specification of the professional system
Note: Feel free to refer to any of the images in this article that included the two gold looking GPUs in a black computer case, as those are actual pictures of the system detailed above.
It is interesting to note that having a high end system is not just about stuffing the best graphics card you can get your hands on into your current system. Other components need to scale up too. System RAM, motherboard, CPU, cooling, and of course power.
The Contenders #

The NVIDIA GeForce GTX 1070 FTW that will be used as the base in this article
NVIDIA GeForce GTX 1070 #
At the bottom of the pack is the GTX 1070, which is readily available to most people, but is still significantly faster than a CPU. It also has a decent amount of GPU RAM at 8GB. A good simple consumer level base.
NVIDIA Tesla T4 #
The Tesla T4 is maybe a strange addition, but there are a few reasons for this.
The first thing to note is that the Tesla T4 is actually a professional graphics card, it is just a few generations old.
In terms of processing speed it is roughly the equivalent of an RTX 2070, but it has double the GPU RAM at 16GB. This additional RAM puts it firmly in the mid range of this test. Current generation consumer cards tend to have RAM in this range (RTX 4070 [12GB] and RTX 4080 [16GB]), so it represents consumer graphics cards in terms of GPU RAM quite nicely.
The final reason is that you can easily access one of these graphics cards for free in Colab. That means anybody reading this article can get their hands dirty and run the code to see for themselves!
The Pro GPU — NVIDIA RTX 6000 Ada #

A view of the two NVIDIA RTX 6000 Ada graphics cards installed in the professional workstation utilised in this article. Image via Exxact Corporation under license to Michael Clayton
There is no doubt about it, the RTX 6000 Ada is an impressive graphics card both in terms of specs…and price. With an MSRP of USD 6,800 it is definitely not a cheap graphics card. So why would you buy one (or more!?) if you can get an RTX 4090 for a mere USD 1599 (MSRP)?
The RTX 4090 has half the RAM and uses 50% more power than the RTX 6000 Ada
I slipped an RTX 4090 into the table to attempt to answer this question. It helps to demonstrate what tend to be the two most obvious differences between a consumer graphics card and a professional graphics card (at least from the specifications alone):
- the amount of GPU RAM available
- the maximum power draw in use
The RTX 4090 has half the RAM and uses 50% more power than the RTX 6000 Ada. This is no accident, as will become evident as the article progresses.
Furthermore, considering the higher power draw of the RTX 4090, it is also worth noting that the RTX 6000 Ada is still roughly 10% faster.
Does this additional RAM and reduced power consumption really make a difference? Hopefully, the comparison will help to answer that later in the article.
Any other less obvious advantages? #
Well, yes. There are a few additional benefits to getting a professional level graphics card.
Reliability #

Image by WikiImages from Pixabay
NVIDIA RTX professional graphics cards are certified with a broad range of professional applications, tested by leading independent software vendors (ISVs) and workstation manufacturers, and backed by a global team of support specialists.
In essence this means the graphics cards are likely to be more reliable and crash resistant, both on a software (drivers), and hardware level, and if you do have a problem, there is an extensive professional network available to solve the problem. These factors are obviously very important for enterprise applications where time is money.
Imagine running a complicated deep learning model for a few days and then losing the results due to a crash or bug. Then spending a significant amount more time potentially dealing with the problem. Not good!
Is this peace of mind an additional reason to pay up? That really depends on your priorities, and scale...
Scale #

Photo by Daniele Levis Pelusi on Unsplash
If you are designing a computer system to have optimal GPU processing power, then it may well be that you need more than one GPU. There will obviously be a limit on how many GPUs can fit in the system based primarily on the availability of motherboard slots, and physical space constraints in the case.
However, there are other limiting factors directly related to the GPU itself, and this is where consumer GPUs and professional GPUs start to deviate in terms of design.
Consider the fact that a professional motherboard may have availability for four dual slot GPUs (like the pro system in this article). So in theory you could fit 4 x RTX 6000 Ada GPUs into the system no problem at all. However, you would only be able to fit 2 x RTX 4090 on the same board. Why? Because the 4090 is a triple slot graphics card (~61mm thick), whereas the 6000 is a dual slot graphics card (~40mm thick).
Consumer level GPUs are just not designed with the same constraints in mind (i.e. high density builds), and therefore start to be less useful as you scale up.
Cooling #
Following on from the potential sizing problem…even if the consumer graphics card was the same dual slot design, there are further issues.
Pro level GPUs tend to be built with cooling systems (blower type) that are designed to draw air through the graphics cards from front to back with a sealed shroud to direct the air straight out of the case (i.e. no hot air recirculating through the case). This allows for pro GPUs to be stacked tightly into the case, and still be able to efficiently cool themselves. All with minimal impact on other components, or GPUs, in the rest of the case.

Two graphics cards one utilising a ‘blower’ cooling system and the other a more common fan cooling system. Photo by Nana Dua on Pexels. Annotations by author.
Consumer GPUs, on the whole, tend to use fan cooling from above/below. This inevitably means hot air from the GPU will recirculate in the case to some degree, necessitating excellent case ventilation.
However, in cases with multiple GPUs, the close proximity of the other graphics cards would make fan cooling very ineffective, and will inevitably lead to sub-optimal temperatures for both the GPUs, and other components in close proximity.
All-in-all professional graphics cards are designed to be tightly and efficiently packed into systems, whilst also staying cool and self contained.
Accuracy #

Photo by Ricardo Arce on Unsplash
This really isn’t particularly relevant to deep learning specifically, but pro GPUs tend to have ECC (Error-Correcting Code) RAM. This would be useful where high precision (i.e. a low level of potential random errors from bit flips) is a must for whatever processes you are running through the graphics card.
However, deep learning models are sometimes tuned to be less numerically precise (half-precision 8-bit calculations), so this is not something that is likely to be of real concern for the calculations being run.
Although if those random bit flips happen to crash your model, then it may just be worth consideration too.
The Deep Learning Model #

Photo by Pixabay
For the deep learning model I wanted something that is advanced, industry leading, and demanding for the GPUs. It also has to be scalable in terms of difficulty as the GPUs on test have a wide range of capabilities.
A pro level model, for a pro level graphics card #
For the model to be industry standard rules out building a model from scratch, so for this comparison an existing, tried and tested, model will be used by utilising transfer learning.
Heavy data #
To ensure the input data is heavy, the analysis will be image based, specifically image classification.
Scalability #
The final criteria is scalability, and there is a particular set of models out there that fits this criteria perfectly…
EfficientNet #
EfficientNet consists of a family of image classification models (B0 to B7). Each model gets progressively more complicated (and accurate). It also has a different expected input shape for the images that you feed in as you progress through the family of models, which increases data input size.
| EfficientNet | Parameters | FLOPs | ImageNet Accuracy | Input Shape |
|---|---|---|---|---|
| B0 | 5.3M | 0.39B | 77.1% | 224x224x3 |
| B1 | 7.8M | 0.70B | 79.1% | 240x240x3 |
| B2 | 9.2M | 1.0B | 80.1% | 260x260x3 |
| B3 | 12M | 1.8B | 81.6% | 300x300x3 |
| B4 | 19M | 4.2B | 82.9% | 380x380x3 |
| B5 | 30M | 9.9B | 83.6% | 456x456x3 |
| B6 | 43M | 19B | 84.0% | 528x528x3 |
| B7 | 66M | 137B | 84.3% | 600x600x3 |
Comparison of the different EfficientNet models — Data from EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks — Table by author
This has a two fold effect:
- as you progress through the different EfficientNet models, the model parameters will increase (i.e. a more complicated and demanding model for the GPUs to process)
- the volume of raw data that needs to be processed will also increase (ranging from 224x224 pixels up to 600x600 pixels)
Ultimately, this gives a large range of possibilities in terms of loading the GPUs both in terms of processing speed and GPU RAM requirements.
The Data #
The data¹ utilised in this article is a set of images which depict the three possible combinations of hand position used in the game rock-paper-scissors.
Four examples from the three different categories of the dataset. Composite image by Author.
Each image is of type PNG, and of dimensions 300(W) pixels x 200(H) pixels, in full colour.
The original dataset contains 2188 images in total, but for this article a smaller selection has been used, which comprises of precisely 2136 images (712 images for each category). This slight reduction in total images from the original has been done simply to balance the classes.
The balanced dataset that was used in this article is available here:

notebooks/datasets/rock_paper_scissors at main · thetestspecimen/notebooks
Jupyter notebooks. Contribute to thetestspecimen/notebooks development by creating an account on GitHub.
The Test #

Photo by Kelly Sikkema on Unsplash
As mentioned previously, there are various levels of EfficientNet available, so for the purposes of testing, the following will be run on each GPU:
- EfficientNet B0 (simple)
- EfficientNet B3 (intermediate)
- EfficientNet B7 (intensive)
This will test the graphics cards speed capabilities due to the difference in overall parameters of each model, but also a wide range of RAM requirements as the input image sizes will vary too.
The EfficientNet models will have all of their layers unlocked and allowed to learn.
The three final models:
EfficientNetB0
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_layer (InputLayer) [(None, 224, 224, 3)] 0
data_augmentation (Sequenti (None, 224, 224, 3) 0
al)
efficientnetb0 (Functional) (None, None, None, 1280) 4049571
global_avg_pool_layer (Glob (None, 1280) 0
alAveragePooling2D)
output_layer (Dense) (None, 3) 3843
=================================================================
Total params: 4,053,414
Trainable params: 4,011,391
Non-trainable params: 42,023
_________________________________________________________________
EfficientNetB3
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_layer (InputLayer) [(None, 300, 300, 3)] 0
data_augmentation (Sequenti (None, 300, 300, 3) 0
al)
efficientnetb3 (Functional) (None, None, None, 1536) 10783535
global_avg_pool_layer (Glob (None, 1536) 0
alAveragePooling2D)
output_layer (Dense) (None, 3) 4611
=================================================================
Total params: 10,788,146
Trainable params: 10,700,843
Non-trainable params: 87,303
_________________________________________________________________
EfficientNetB7
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_layer (InputLayer) [(None, 600, 600, 3)] 0
data_augmentation (Sequenti (None, 600, 600, 3) 0
al)
efficientnetb7 (Functional) (None, None, None, 2560) 64097687
global_avg_pool_layer (Glob (None, 2560) 0
alAveragePooling2D)
output_layer (Dense) (None, 3) 7683
=================================================================
Total params: 64,105,370
Trainable params: 63,794,643
Non-trainable params: 310,727
_________________________________________________________________Speed Test #
The speed of the GPUs will be judged by how quickly they can complete an epoch.
To be more specific, there will be a minimum of two epochs run on each graphics card, and the second epoch will be used to judge the processing speed. The first epoch generally has some additional loading time, so would not be a good reference for general execution time.
The time to run the first epoch will be listed only for reference.
GPU RAM Test #
To test the limits of the GPU RAM, the batch size for each graphics card, and each EfficientNet model (i.e. B0, B3 or B7), has been tuned to be as close as possible to the limit for that particular graphics card (i.e. to fill the GPU RAM as much as possible).
The actual peak GPU RAM utilisation for the run will also be disclosed for comparison.
The Code #

Photo by Oskar Yildiz on Unsplash
As ever, I have made all the python scripts (GTX 1070 and RTX 6000 Ada) and notebooks (Tesla T4) available on GitHub:

notebooks/pro-vs-consumer-graphics-card at main · thetestspecimen/notebooks
Jupyter notebooks. Contribute to thetestspecimen/notebooks development by creating an account on GitHub.
You can also access the notebooks for the Tesla T4 directly on Colab if you so wish:
EfficientNetB0:
![]()
EfficientNetB3:
![]()
EfficientNetB7:
![]()
The Results #

Photo by Pixabay
EfficientNet B0 #
| Card | 1st Epoch [s] | 2nd Epoch [s] | Batch Size | Peak RAM [GB] |
|---|---|---|---|---|
| GTX 1070 | 47 (+30s) | 17 | 60 | 6.91 |
| Tesla T4 | 67 (+40s) | 17 | 128 | 13.2 |
| RTX 6000 ada | 26 (+20s) | 4 | 512 | 47.7 |
| 2 x RTX 6000 ada | 39 (+38s) | 1 | 1024 | 47.7 (each) |
EfficientNet B3 #
| Card | 1st Epoch [s] | 2nd Epoch [s] | Batch Size | Peak RAM [GB] |
|---|---|---|---|---|
| GTX 1070 | 108 (+46s) | 62 | 16 | 5.9 |
| Tesla T4 | 129 (+74s) | 55 | 40 | 13.7 |
| RTX 6000 ada | 46 (+33s) | 13 | 128 | 40.6 |
| 2 x RTX 6000 ada | 65 (+57s) | 8 | 256 | 41.2 (each) |
EfficientNet B7 #
| Card | 1st Epoch [s] | 2nd Epoch [s] | Batch Size | Peak RAM [GB] |
|---|---|---|---|---|
| GTX 1070 | 953 (+95s) | 858 | 1 | 5.1 |
| Tesla T4 | 839 (+161s) | 678 | 2 | 9.9 |
| RTX 6000 ada | 213 (+69s) | 144 | 10 | 44.6 |
| 2 x RTX 6000 ada | 203 (+125s) | 78 | 20 | 41.8 (each) |
Note: for the first epoch I have listed a number of seconds in brackets. This is the time difference between the first and second epoch.
Discussion — Execution Speed #

Image by Arek Socha from Pixabay
The first item to look at is execution speed.
EfficientNet B0 doesn’t cause much of a challenge for any of the graphics cards with this particular dataset, with all completing an epoch in a matter of seconds.
However, it is important to remember that the dataset utilised in this article is small, and in reality the two RTX 6000 Ada graphics cards are approximately 17 times faster that the GTX 1070 (and Tesla T4) in terms of execution speed. The story is pretty much the same for EfficientNet B3 (8x faster) and B7 (11x faster).
The difference is that this slow down in speed, when viewed as execution time, starts to become more of a hindrance the more complicated the model gets.
For example, to execute a single epoch, on this very small dataset, using EfficientNet B7 with a GTX 1070 takes approximately 15 mins. Compare that to just over 1 minute with a pair of RTX 6000 Ada.
…and it gets worse.
Scaling up #
Let’s be realistic. No model is going to converge in one epoch. Four hundred might be a more reasonable number for a model like EfficientNet.
That would be the difference between 4 days on a GPU like the GTX 1070, and only a few hours (6.5 to be precise) on a dual RTX 6000 Ada setup. Then consider that a real dataset doesn’t have only 2188 images, it could have millions (for reference ImageNet has just over 14 million images).
Industry progress #
Another thing to bear in mind is progress in industry. EfficientNet is a few years old now, and things have moved on.
As a small example take NoisyStudent, which builds on the standard EfficientNets with a variation called EfficientNet-L2 and states:
Due to the large model size, the training time of EfficientNet-L2 is approximately five times the training time of EfficientNet-B7
-Self-training with Noisy Student improves ImageNet classification
…so speed really does matter if you need to stay at the cutting edge.
What does that mean for pro vs consumer graphics cards then? #
The truth is that if you only look at speed of execution there is very little difference between professional and consumer GPUs if you compare like for like. An RTX 4090 is near as makes no difference the same speed as an RTX 6000 Ada.
An RTX 4090 is near as makes no difference the same speed as an RTX 6000 Ada.
All this little experiment has illustrated so far is that speed is very important, as industry standard models are progressing in complexity quite quickly. Older generation graphics cards are noticeably slower already. To keep up requires at least staying on the cutting edge of hardware.
…scale matters a great deal when answering this question.
…but with the speed of progression (just look at the rapid accent of GTP-3 and GTP-4) it also appears that if you want to stay at the cutting edge, one GPU, even at the level of the RTX 4090 or RTX 6000 Ada, is unlikely to be enough. If that is the case, then the superior cooling, less power draw and more compact size of the professional level graphics cards are a significant advantage when building a system.
Essentially, scale matters a great deal when answering this question.
However, speed is only one facet. Now let’s move on to the GPU RAM, where things get a little more interesting…
Discussion — GPU RAM #
GPU RAM is a significant consideration in some situations, and can be a literal limiting factor as to whether certain models, or datasets, can be utilised at all.
Let’s see the pair of RTX 6000 Ada in full flow:
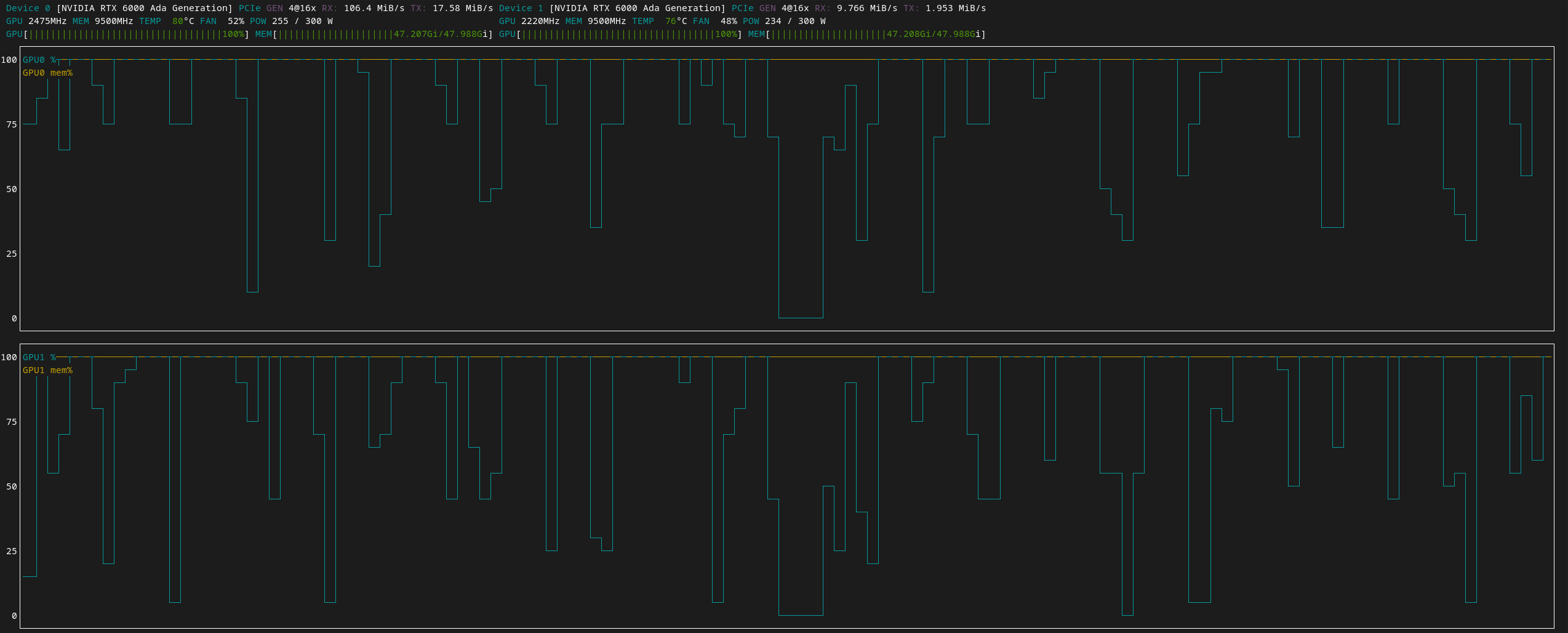
The two RTX 6000 Ada GPUs running a deep learning model. Image by Author
You may notice in the image above that the GPU RAM is at 100% for both GPUs. However, the this is not the real usage:
By default, TensorFlow maps nearly all of the GPU memory of all GPUs (subject to
*CUDA_VISIBLE_DEVICES*) visible to the process. This is done to more efficiently use the relatively precious GPU memory resources on the devices by reducing memory fragmentation.
The limits #
The absolute limit is brought home quite starkly by the fact that the GTX 1070 (which has 8GB of GPU RAM) is only capable of running EfficientNet B7 with a batch size of 1 (i.e. it can process 1 image at a time before having to update the model parameters and load the next image into the GPU RAM).
This causes two problems:
- You lose speed of execution due to frequent parameter updates in addition to loading in fresh data to the GPU RAM more regularly (i.e. larger batch sizes are inherently quicker.)
- If the input image size gets any larger, the model will not be able to run at all, as it won’t fit one single image into the GPU RAM
Even the Tesla T4 which has a not too shabby 16GB of GPU memory only manages a batch size of 2 on EfficientNet B7.
As detailed earlier, 16GB of GPU RAM is a good representation of the majority of current generation consumer GPUs, with only the RTX 4090 having more at 24GB. So this is a fairly significant downfall for consumer GPUs if you are dealing with memory heavy raw data.
At this point it suddenly becomes clear why all the professional GPUs are so RAM heavy when compared to their consumer equivalents. As mentioned in the discussion for the speed of execution, EfficientNet is no longer at the bleeding edge, so the reality today is probably even more demanding than outlined in the tests for this article.
System density #
Another consideration in regard to GPU RAM is system density.
For example, the system I have been given access to has a motherboard that can take 4 double height GPUs (I have also seen systems with up to 8 GPUs). This means that if GPU RAM is a priority in your system, then professional GPUs are a no brainer:
4 x RTX 6000 Ada = 192GB GPU RAM and 1200W of power draw
4 x RTX 4090 = 96GB GPU RAM and 1800W of power draw
(…and as I have already mentioned earlier in the article the RTX 4090 is a triple slot GPU so this isn’t even realistic. In reality only two RTX 4090 graphics cards would actually fit, but for the sake of easy comparison let’s assume it would work.)
That is no small difference. To match the RTX 6000 Ada system in terms of GPU RAM you would need two separate systems drawing at least three times the power.
To match the RTX 6000 Ada system in terms of RAM you would need two separate systems drawing at least three times the power.
Don’t forget that as you would need two separate systems, you would have to fork out for additional CPUs, power supplies, motherboards, cooling, cases etc.
A side note on system RAM… #

Did you notice 8 sticks of 64GB system RAM above and below the CPU in the professional system? Image via Exxact Corporation under license to Michael Clayton
It is also worth pointing out, that it is not just the GPU RAM that matters. As the GPU RAM scales up you need to increase the system RAM in parallel.
You may note in the Jupyter notebooks for the Tesla T4 that I have commented out the following optimisations:
train_data = train_data.cache().prefetch(buffer_size=tf.data.AUTOTUNE)
val_data = val_data.cache().prefetch(buffer_size=tf.data.AUTOTUNE)This is because, for EfficientNet B7, the training will crash if they are enabled.
Why?
Because the “.cache()” optimisation keeps the data in system memory to feed it efficiently to the GPU, and the Colab instance only has 12GB of system memory. Which is not enough, even though the GPU RAM peaks at 9.9GB:
This [.cache()] will save some operations (like file opening and data reading) from being executed during each epoch.
However, the professional system has 8 sticks of 64GB system RAM, for a total of 512GB of system RAM. So even though the two RTX 6000 Ada GPUs combined have 96GB of GPU RAM, there is still plenty of overhead in the system RAM to deal with heavy caching.
Conclusion #

Image via Exxact Corporation under license to Michael Clayton
So, are professional level graphics cards better than consumer cards for deep learning?
Money no object. Yes, they are.
Does that mean that you should discard considering consumer level graphics cards for deep learning?
No, it doesn’t.
It all comes down to specific requirements, and more often than not scale.
Large datasets #
If you know that your workload is going to be RAM intensive (large language models, image, or video based analysis for example) then professional graphics cards of the same generation and processing speed tend to have roughly double the GPU RAM.
It all comes down to specific requirements, and scale.
This is a significant advantage, especially considering there is no elevation in energy requirements to achieve this compared to a consumer graphics card.
Smaller datasets #
If you don’t have high RAM requirements, then the question is more nuanced and relies on whether reliability, compatibility, support, energy consumption, and that additional 10% in terms of speed are worth the quite significant hike in price.
Scale #
If you are about to invest in significant infrastructure, then reliability, energy consumption and system density may move from low priority to quite significant considerations. Areas that professional GPUs excel at.
Conversely, if you need a smaller system, and high GPU RAM requirements aren’t important, then considering consumer level graphics cards may turn out to be beneficial. Factors associated with large scale, such as reliability and energy consumption will become less of an issue, and system density won’t matter at all.
The final word #
All in all it is a balancing act, but if I had to pick two items to summarise the most important factors in choosing between a consumer GPU and professional GPU it would be:
- GPU RAM
- System scale
If you have either high GPU RAM requirements, or will need larger systems with multiple GPUs, then you need a professional level GPU/GPUs.
Otherwise, most likely, consumer level will be a better deal.
🙏🙏🙏
Since you've made it this far, sharing this article on your favorite social media network would be highly appreciated. For feedback, please ping me on Twitter.
...or if you want fuel my next article, you could always:

Published